
Mode Help
Query and analyze data
Querying data
Overview
The report is where analysis happens in Mode. Navigate to the Mode home page and click the New ![]() button in the upper right corner of the window to create a new report and get started. All new reports are automatically added to your Personal Collection.
button in the upper right corner of the window to create a new report and get started. All new reports are automatically added to your Personal Collection.
After creating a Report, you will be taken to the editor to write your first query.
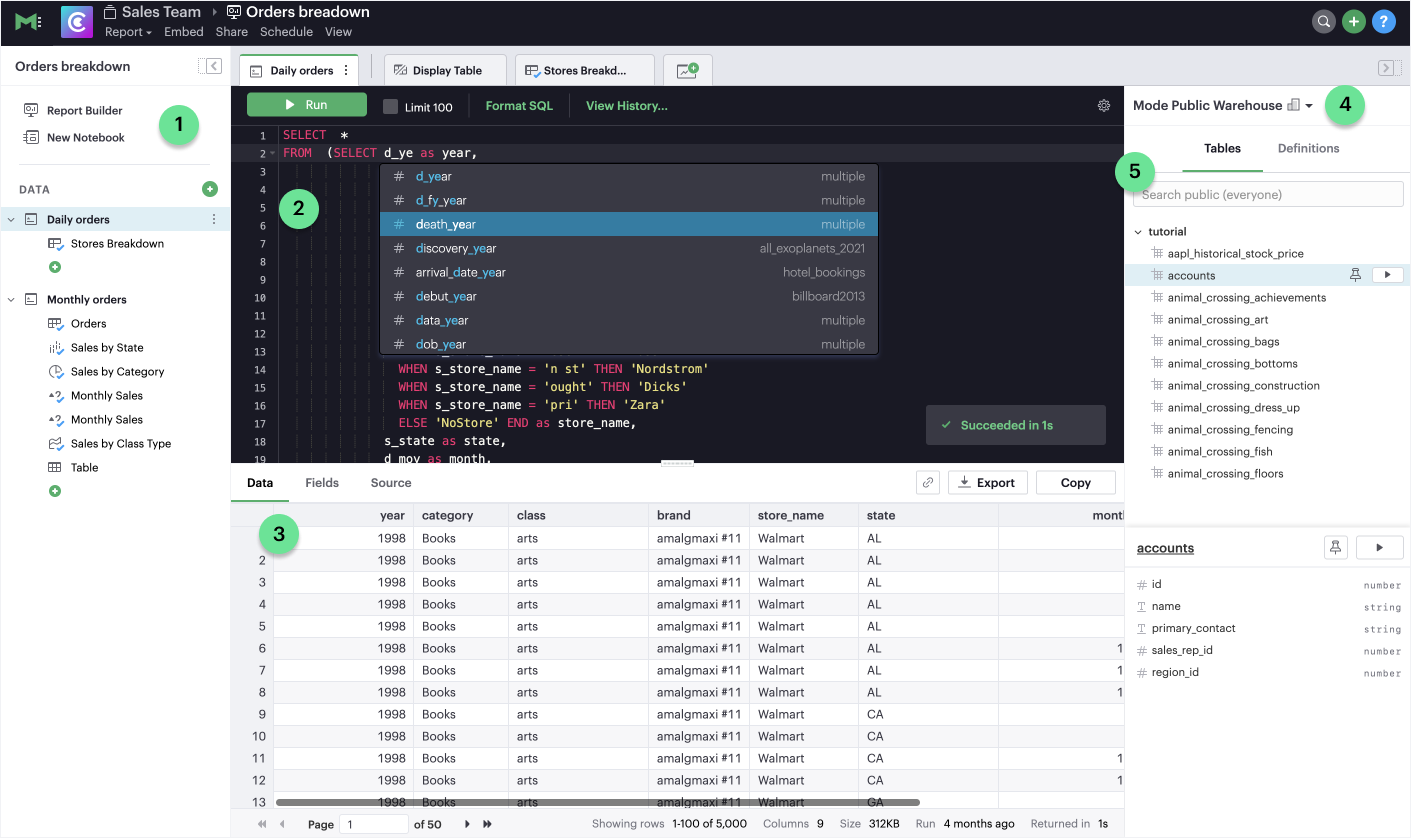
The query editor contains a number of re-sizable sections that should be familiar to you if you have worked with other SQL clients before:
- Report navigation panel - Use the navigation panel to quickly navigate between the Report Builder, a Python/R Notebook, and the data section. Within the data section, which you can drag to resize, you will see:
- Every query and reusable Dataset in the Report. Click on a Query to select it and edit its code. Use the context menu to rename, duplicate, delete, reorder and more. To add a new query or Dataset, click on the plus button to the right of the Data header. Drag and drop to reorder the queries and Datasets.
- Each visualization that you build using a query's data. Use the overflow menu to add or remove your Chart from the Report Builder, duplicate, explore, and more. Or, click the plus button below your chart to add a new one
-
Code editor: Compose your SQL code here. The code editor is powered by Ace and supports most Ace keyboard shortcuts and context-aware autocomplete for database objects (e.g., column and table names), SQL keywords, and Definitions. Across the top of the query editor are a number of controls:
- Run: Executes all code in the editor. Select a portion of your code before clicking Run to execute only that portion.
- Limit 100: Checked by default. Automatically appends
LIMIT 100to your query so no more than 100 rows are returned in the result set. This speeds up exploratory querying but should be unchecked once you want to see a complete result set. - Format SQL: Automatically indents and formats your SQL code for you. If you don't like how it formats your code, click it again to revert.
- View History: The running history of each query execution, including the raw code (as written), rendered code (SQL sent to the database after processing all Liquid code), and any data that was returned. Select a historical query run and click Open to replace the code currently in the query editor with the code from that run.
- Editor Settings: Toggle on/off settings for the code editor. These options allow you to personalize the editor to fit your preferences. Choose between light and dark modes, side-by-side or stacked panels, Limit 100 on/off by default, and other helpful autocomplete settings. To turn autocomplete on or off, you can toggle the switch in the Autocomplete Settings or you can disable (and re-enable) it by hitting CMD + Option + a (Control + ALT + a on a PC) in the editor.
-
Data view: After you successfully execute a SQL query, the tabular results, fields, and syntax are displayed here, which you can drag to resize.
- Use the Data tab to consume your results, share the URL to that specific query, export the raw query data as a CSV, or copy the data to the clipboard

- Use the Fields tab to view meta-data about your fields, add new Calculated fields, and edit, rename, or remove existing Calculated fields

- Use the Source tab to toggle between the raw and rendered SQL that was executed at the time of the run, and copy the syntax to the clipboard

-
Database dropdown: Tells Mode which connection to query and which database's schemas and tables to display in the schema browser.
-
Schema Browser: A visual representation of the schemas, tables and columns that are available in the selected database, which you can drag to resize.
Schema browser
The schema browser lets you explore the schemas, tables and columns in the selected database. Drag to resize to fit longer table names.
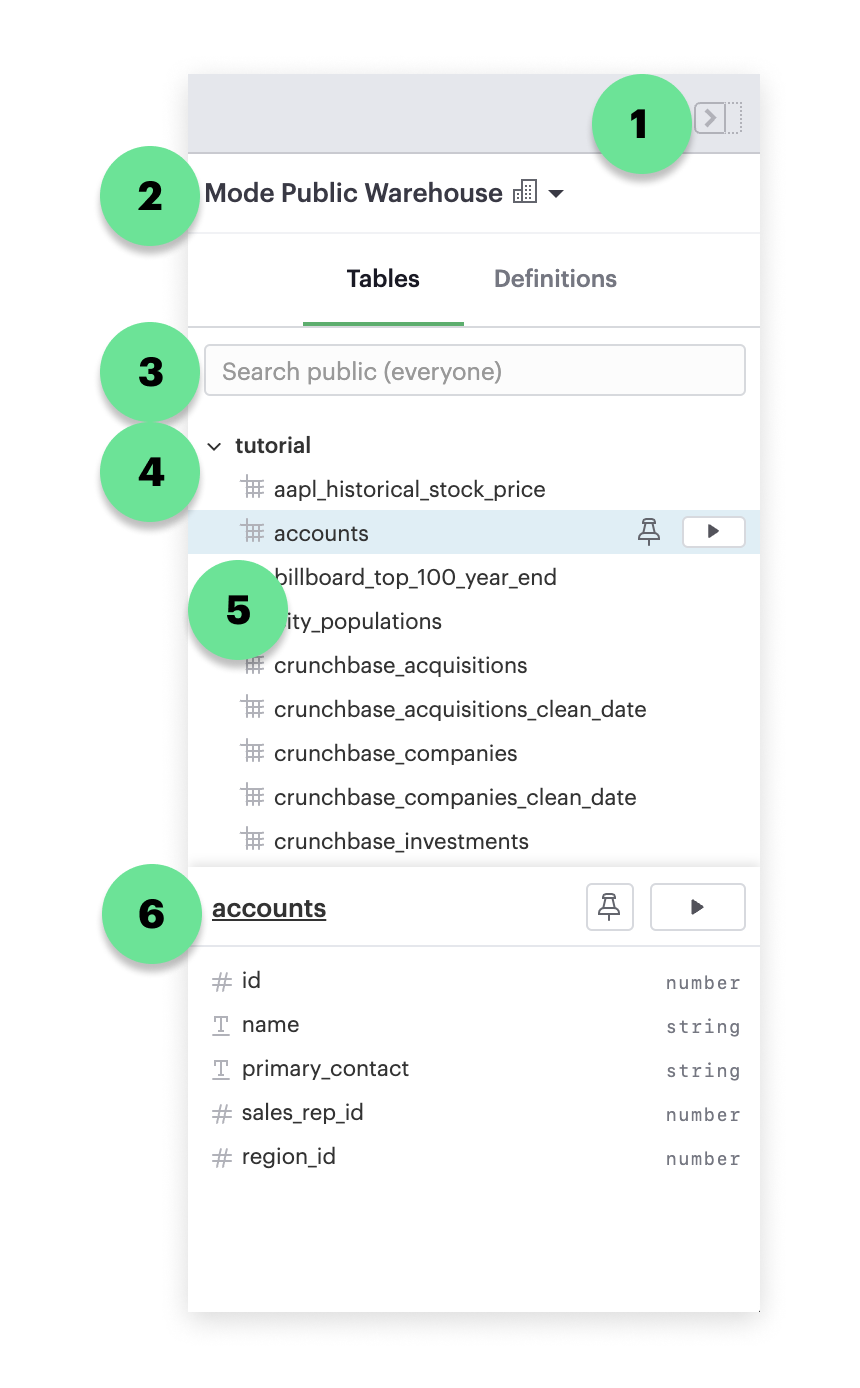
- Show/hide: Click to hide or reveal the schema browser.
- Selected data connection: Click to reveal and select from a list of data connections. The schema browser will show tables for the database displayed here. The query will also execute against this connection.
- Search: Type to search for table names in the selected database.
- Pinned: Tables you "pin" are shown at the top of the schema browser so you can easily find them. Tables are automatically pinned as you query them. To pin a table, hover over its name and click the pin
 icon on the right.
icon on the right. - Tables: All the tables that you have access to for a given data connection are listed here, organized by schema. Click the play button next to any table name to quickly return a sampling of 100 rows from that table.
- Columns: A list of all the columns in a selected table. The symbol next to the column name refers to the type of data in that column (e.g., varchar, float, date, etc.).
Querying multiple data sources
Mode reports can contain multiple queries, and each individual query can retrieve data from any one connected database. Different visualizations, each with data from different databases, can exist side-by-side within the same report.
You cannot JOIN data sets between different connections in a single query. However, you can combine result sets from multiple databases and visualize the combined data using Python or R in the Notebook, or using JavaScript in the HTML editor.
Complex and multi-statement queries
Mode performs very little translation or manipulation of your code before sending it to your database for execution. This means that Mode will be able to execute any code that's valid for your database. Given the right database permissions, you aren't limited to SELECT statements; you can do anything your database lets you do, including:
- Creating, dropping, and altering tables and views
- INSERT, DELETE and UPDATE operations
- Creating, modifying, or employing user-defined functions
Mode will execute code containing multiple SQL statements, separated by semi-colons. For example, the following code is valid in Mode:
SET TIME ZONE 'UTC';
SET search_path TO schema_name;
CREATE TEMP TABLE temp1 AS
(
SELECT email, company, LOCALTIME AS date FROM customers
);
SELECT * FROM temp1;
Extending SQL with Liquid
Overview
You can extend the power of your SQL queries in many interesting ways by using the open source Liquid template language. Using Liquid, the SQL behind your Mode reports can be manipulated at report run time using loops, if/then statements, and other advanced structures that might be difficult or impossible to do in SQL alone. Several examples of these methods are shown below.
Whenever a query is executed in a Mode report, Liquid code (if present) is evaluated first before the code is sent to your database for execution as SQL. Liquid code is composed of:
Objects contain attributes that are used to render dynamic content into your SQL query at run time. Objects are wrapped in double curly brackets {{...}}.
Filters are simple methods that modify the output of numbers, strings, variables and objects. They are placed inside Object tags {{ }} and denoted with a | character.
Tags make up the programming logic (e.g., if/else, for, etc.) that tells your code what to do. They are wrapped in a single curly bracket and a percent sign {%...%}. Tags don't themselves produce output that gets rendered into your query, but they may instruct Mode to render, ignore, repeat or otherwise modify specific lines of SQL code.
Full documentation on what's possible with Liquid is available on the Shopify help site and documentation for the Liquid GitHub repo.
Common techniques
Variables
Use variables in Liquid to make your code more extensible and maintainable. Declare a variable using the assign method. For example:
SELECT * FROM employee_table WHERE favorite_food = '{{ fav_food }}'
{% assign fav_food = 'peaches' %}
The above code would render into the following code for execution against the database:
SELECT * FROM employee_table WHERE favorite_food = 'peaches'
assign. They cannot be referenced across reports or across queries within the same report.
If/else
Use if/else statements and other control flow tags to change your SQL code dynamically in response to inputs from things like variables or parameters. In the following example, the query that is executed against the database will be different depending on the value of the car_type variable:
{% assign car_type = 'trucks' %}
SELECT *
{% if car_type == 'trucks' %}
FROM truck_table
{% elsif car_type == 'cars' %}
FROM car_table
{% endif %}
If car_type = 'trucks', the following code is executed:
SELECT * FROM truck_table
If car_type = 'cars', the following code is executed:
SELECT * FROM car_table
Loops
Loops and other Liquid iteration tags can be used to programmatically generate lists of variables, join statements, columns to select, unions and other things. The query below shows a simple example of a For loop:
SELECT *
FROM sports_teams
{% for i in (1..4) %}
LEFT JOIN draft_picks d{{i}}
ON d{{i}}.team_name = sports_teams.team_name
AND d{{i}}.round = {{i}}
{% endfor %}
The above code joins the draft_picks table to the teams table four times. Each join is assigned a distinct alias (d1 through d4) and a different condition (the round number of the draft pick). The rendered code that is actually sent to the database for execution is:
SELECT *
FROM sports_teams
LEFT JOIN draft_picks d1 ON d1.team_name = sports_teams.team_name AND d1.round = 1
LEFT JOIN draft_picks d2 ON d2.team_name = sports_teams.team_name AND d2.round = 2
LEFT JOIN draft_picks d3 ON d3.team_name = sports_teams.team_name AND d3.round = 3
LEFT JOIN draft_picks d4 ON d4.team_name = sports_teams.team_name AND d4.round = 4
In some cases you may want the last iteration of the loop to produce a different result than other iterations. For example, if you're creating a list of strings separated by commas, you might want a comma after every value except the last one. Liquid includes a forloop.last statement that makes this easy:
WHERE name IN (
{% for name in list_of_names %}
'{{name}}'
{% unless forloop.last %}
,
{% endunless %}
{% endfor %}
)
For every iteration of the loop except the last one, forloop.last returns false. Therefore, the value in the unless statement---a comma---gets added to your query after every name except the last one.
This query contains two examples of a loop. This query, which uses the assign method below, shows one example.
Array Variables
Typically, for loops cycle through collections of values, such as iterable objects in Python or vectors in R. Liquid doesn't allow you to create arrays of values the same way you would in most languages (e.g. list = ['candy','beans']). To create an array that you can iterate over in a for loop, you have to use the split filter on a delimited string and assign the result to a variable. For example:
{% assign food = 'candy,beans,pizza' | split: "," %}
{% for item in food %}
LEFT JOIN types_of_food {{ item }}
ON {{ item }}.type = '{{ item }}'
{% endfor %}
The above code converts the comma delimited string 'candy,beans,pizza' to an array and assigns that array to the variable food. The for loop then iterates over each value in the array variable food.
Comments
Use {% comment %} and {% endcomment %} tags to instruct Mode to ignore whatever text or code is written between them.
Parameters
Parameters allow you to define forms that are configurable by viewers of your report and which return Liquid objects in your report's code. Parameters are a great way to make reports more extensible, maintainable, and scalable.
Query headers
Liquid templates can be used when defining custom query headers in data sources connected to your Mode Workspace. A custom query header is prepended to every query run against that data source and is a great way to increase logging fidelity in your database.
SQL keyboard shortcuts
Mode's SQL Editor runs using the Ace Editor library, and we have enabled most of the default keyboard shortcuts for things like commenting or indenting blocks of text. We've also added some Mode-specific keyboard shortcuts:
General
| Action | Mac | PC |
|---|---|---|
| Run query | ⌘ Return | Ctrl Enter |
| Save query | ⌘ S | Ctrl S |
| Switch to Report Builder | Ctrl I | Alt I |
| Indent | Tab | Tab |
| Outdent | Shift Tab | Shift Tab |
| Add multi-cursor above | Ctrl Option ↑ | Ctrl Alt ↑ |
| Add multi-cursor below | Ctrl Option ↓ | Ctrl Alt ↓ |
| Undo | ⌘ Z | Ctrl Z |
| Redo | ⌘ Y | Ctrl Y |
| Toggle comment | ⌘ / | Ctrl / |
| Change to lower case | Ctrl Shift U | Ctrl Shift U |
| Change to upper case | Ctrl U | Ctrl U |
| Fold selection | ⌘ F1 | Ctrl F1 |
| Unfold | ⌘ Shift F1 | Ctrl Shift F1 |
| Find | ⌘ F | Ctrl F |
| Replace | ⌘ Option F | Ctrl H |
| Find next | ⌘ G | Ctrl K |
| Find previous | ⌘ Shift G | Ctrl Shift K |
| Open autocomplete | Ctrl Space | Ctrl Space |
Selection
| Action | Mac | PC |
|---|---|---|
| Select All | ⌘ A | Ctrl A |
| Select left | Shift ← | Shift ← |
| Select right | Shift → | Shift → |
| Select word left | Option Shift ← | Ctrl Shift ← |
| Select word right | Option Shift → | Ctrl Shift → |
| Select to line start | ⌘ Shift ← | Alt Shift ← |
| Select to line end | ⌘ Shift → | Alt Shift → |
| Select up | Shift ↑ | Shift ↑ |
| Select down | Shift ↓ | Shift ↓ |
| Duplicate selection | ⌘ Shift D | Ctrl Shift D |
Go to
| Action | Mac | PC |
|---|---|---|
| Go to word left | Option ← | Ctrl ← |
| Go to word right | Option → | Ctrl → |
| Go line up | Ctrl P | ↑ |
| Go line down | Ctrl N | ↓ |
| Go to line start | ⌘ ← | Alt ← |
| Go to line end | ⌘ Shift ← | Alt → |
| Go to start | ⌘ ↑ | Ctrl Home |
| Go to end | ⌘ ↓ | Ctrl End |
Line operations
| Action | Mac | PC |
|---|---|---|
| Remove line | ⌘ D | Ctrl D |
| Copy lines down | Option Shift ↓ | Alt Shift ↓ |
| Copy lines up | Option Shift ↑ | Alt Shift ↑ |
| Move lines down | Option ↓ | Alt ↓ |
| Move lines up | Option ↑ | Alt ↑ |
| Remove to line end | Ctrl K | |
| Remove to line start | ⌘ Backspace | Alt Backspace |
| Remove word left | Option Backspace | Ctrl Backspace |
| Remove word right | Option Delete | Ctrl Delete |
FAQs
Q: The schema browser is empty or missing tables I know to be in the database
The tables listed in Mode's schema browser may differ from what you expect for a number of reasons:
-
The database was recently connected or updated
Mode's schema browser updates once daily at 10:05am UTC / 2:05am PST / 5:05am EST. If you recently connected a new database, an automatic update is triggered and the schema browser may appear blank for 30 minutes or more until the refresh completes. If new tables were added to an existing database, you will need to manually trigger the schema refresh to see the updates. To instruct Mode to perform a schema browser refresh, click on the
 button in the upper right corner of the schema browser and click Refresh.
button in the upper right corner of the schema browser and click Refresh.New tables and databases, however, may be queried immediately regardless of whether or not they appear in the schema browser.
-
You don't have permission to see the missing tables
Mode connects to your database as a database user. This user, which is defined by your database, may not have access to all of the tables in your database. If you think this might be the case, try querying one of the tables that's missing from the schema browser. If the query returns an error saying you don't have permission to access that table, this is likely the issue.
Resolve this issue by granting the database user access to the missing tables. These configurations are defined by the database and typically managed by database admins. These permissions cannot be changed directly in Mode.
Q: Does Mode time-out long running queries or reports?
Mode will cancel any incomplete queries or report runs after a certain period of time to prevent long-running queries from degrading the performance of Mode or your database. Note that your database may be configured to time-out queries sooner than the times listed below:
| Scenario | Time-out after |
|---|---|
| Manual query / report run | 12 hours |
| Scheduled run (daily / weekly / monthly) | 12 hours |
| Scheduled run (hourly) | 1 hour |
| Scheduled run (every 30 minutes) | 30 minutes |
| Scheduled run (every 15 minutes) | 15 minutes |
Q: In what order are queries executed during a report and scheduled run?
Queries are initiated simultaneously and the results are returned based on the processing time of your database. This allows for efficient and concurrent query processing, ensuring that your queries are executed as quickly as possible. By starting queries simultaneously, we can maximize the use of your database resources and minimize the overall time it takes to retrieve the results of your queries.
Q: Does Mode support real-time data?
At this time, Mode does not maintain active connections to client databases for security and data cost purposes, and does not support real-time data. All reports, whether scheduled or ad hoc, create new connections on demand.
Please see our documentation on how to schedule a report. We also suggest taking a look at our Datasets documentation. This allows multiple reports to be created off of an initial query, which can be set to refresh on a schedule as well.
Q: What type and version of SQL does Mode use for the Public Warehouse?
Our Mode Public Warehouse is a PostgreSQL data source using version 13.1. When connecting to a private database, Mode does not enforce any specific SQL syntax. Instead, we support any version of SQL that your connected database supports, allowing you to use the full capabilities of your database without any limitations. This allows you to use the most up-to-date SQL features and ensures that your queries are optimized for your specific database environment.
Q: Is there a query limit for reports?
Yes, currently the limit is 160 queries per report.
Troubleshooting
1. Sorry, this data is larger than your limit
Mode limits the size of query results that you can access depending on whether you're using Mode Studio, or which paid plan you've chosen.
For Mode Business and Enterprise customers, we offer different plans that support increased capacity up to 10 GB.
2. Query result is too large. Please try adding a LIMIT clause
Query results over 10 GB cannot be returned to Mode from a database. If your results exceed this limit, add a LIMIT statement to your query to return a smaller set of results.
Was this article helpful?