
Python Tutorial
Learn Python for business analysis using real-world data. No coding experience necessary.
Start Now
Mode Studio
The Collaborative Data Science Platform
Pivoting Data in SQL
Starting here? This lesson is part of a full-length tutorial in using SQL for Data Analysis. Check out the beginning.
In this lesson we'll cover:
Pivoting rows to columns
This lesson will teach you how to take data that is formatted for analysis and pivot it for presentation or charting. We'll take a dataset that looks like this:
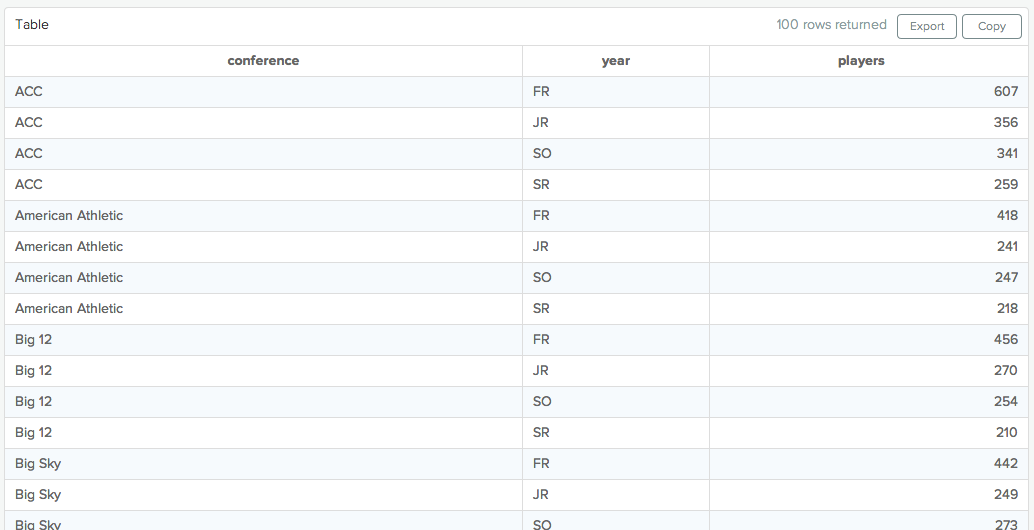
And make it look like this:
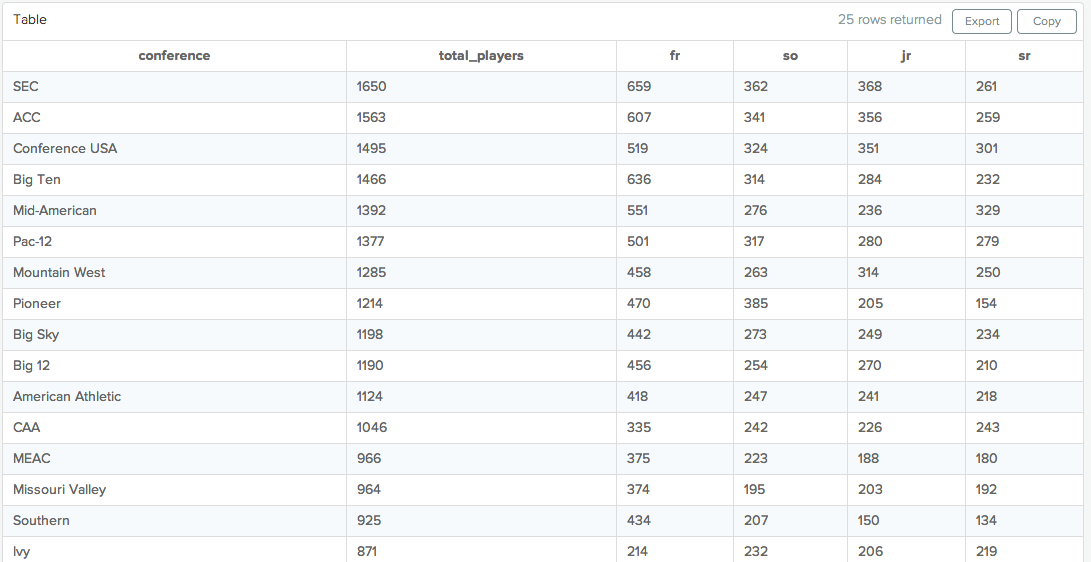
For this example, we'll use the same dataset of College Football players used in the CASE lesson. You can view the data directly here.
Let's start by aggregating the data to show the number of players of each year in each conference, similar to the first example in the inner join lesson:
SELECT teams.conference AS conference,
players.year,
COUNT(1) AS players
FROM benn.college_football_players players
JOIN benn.college_football_teams teams
ON teams.school_name = players.school_name
GROUP BY 1,2
ORDER BY 1,2
In order to transform the data, we'll need to put the above query into a subquery. It can be helpful to create the subquery and select all columns from it before starting to make transformations. Re-running the query at incremental steps like this makes it easier to debug if your query doesn't run. Note that you can eliminate the ORDER BY clause from the subquery since we'll reorder the results in the outer query.
SELECT *
FROM (
SELECT teams.conference AS conference,
players.year,
COUNT(1) AS players
FROM benn.college_football_players players
JOIN benn.college_football_teams teams
ON teams.school_name = players.school_name
GROUP BY 1,2
) sub
Assuming that works as planned (results should look exactly the same as the first query), it's time to break the results out into different columns for various years. Each item in the SELECT statement creates a column, so you'll have to create a separate column for each year:
SELECT conference,
SUM(CASE WHEN year = 'FR' THEN players ELSE NULL END) AS fr,
SUM(CASE WHEN year = 'SO' THEN players ELSE NULL END) AS so,
SUM(CASE WHEN year = 'JR' THEN players ELSE NULL END) AS jr,
SUM(CASE WHEN year = 'SR' THEN players ELSE NULL END) AS sr
FROM (
SELECT teams.conference AS conference,
players.year,
COUNT(1) AS players
FROM benn.college_football_players players
JOIN benn.college_football_teams teams
ON teams.school_name = players.school_name
GROUP BY 1,2
) sub
GROUP BY 1
ORDER BY 1
Technically, you've now accomplished the goal of this tutorial. But this could still be made a little better. You'll notice that the above query produces a list that is ordered alphabetically by Conference. It might make more sense to add a "total players" column and order by that (largest to smallest):
SELECT conference,
SUM(players) AS total_players,
SUM(CASE WHEN year = 'FR' THEN players ELSE NULL END) AS fr,
SUM(CASE WHEN year = 'SO' THEN players ELSE NULL END) AS so,
SUM(CASE WHEN year = 'JR' THEN players ELSE NULL END) AS jr,
SUM(CASE WHEN year = 'SR' THEN players ELSE NULL END) AS sr
FROM (
SELECT teams.conference AS conference,
players.year,
COUNT(1) AS players
FROM benn.college_football_players players
JOIN benn.college_football_teams teams
ON teams.school_name = players.school_name
GROUP BY 1,2
) sub
GROUP BY 1
ORDER BY 2 DESC
And you're done! View this in Mode.
Pivoting columns to rows
A lot of data you'll find out there on the internet is formatted for consumption, not analysis. Take, for example, this table showing the number of earthquakes worldwide from 2000-2012:
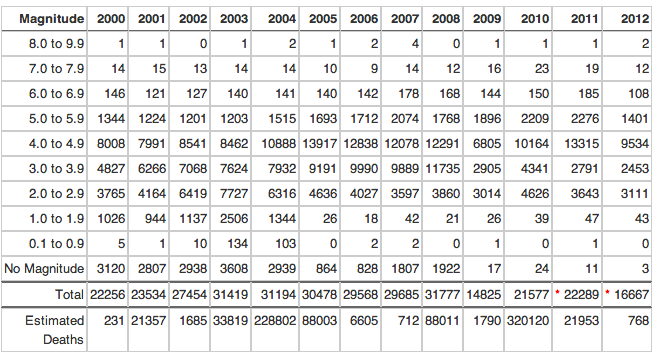
In this format it's challenging to answer questions like "what's the average magnitude of an earthquake?" It would be much easier if the data were displayed in 3 columns: "magnitude", "year", and "number of earthquakes." Here's how to transform the data into that form:
First, check out this data in Mode:
SELECT *
FROM tutorial.worldwide_earthquakes
Note: column names begin with 'year_' because Mode requires column names to begin with letters.
The first thing to do here is to create a table that lists all of the columns from the original table as rows in a new table. Unless you have a ton of columns to transform, the easiest way is often just to list them out in a subquery:
SELECT year
FROM (VALUES (2000),(2001),(2002),(2003),(2004),(2005),(2006),
(2007),(2008),(2009),(2010),(2011),(2012)) v(year)
Once you've got this, you can cross join it with the worldwide_earthquakes table to create an expanded view:
SELECT years.*,
earthquakes.*
FROM tutorial.worldwide_earthquakes earthquakes
CROSS JOIN (
SELECT year
FROM (VALUES (2000),(2001),(2002),(2003),(2004),(2005),(2006),
(2007),(2008),(2009),(2010),(2011),(2012)) v(year)
) years
Notice that each row in the worldwide_earthquakes is replicated 13 times. The last thing to do is to fix this using a CASE statement that pulls data from the correct column in the worldwide_earthquakes table given the value in the year column:
SELECT years.*,
earthquakes.magnitude,
CASE year
WHEN 2000 THEN year_2000
WHEN 2001 THEN year_2001
WHEN 2002 THEN year_2002
WHEN 2003 THEN year_2003
WHEN 2004 THEN year_2004
WHEN 2005 THEN year_2005
WHEN 2006 THEN year_2006
WHEN 2007 THEN year_2007
WHEN 2008 THEN year_2008
WHEN 2009 THEN year_2009
WHEN 2010 THEN year_2010
WHEN 2011 THEN year_2011
WHEN 2012 THEN year_2012
ELSE NULL END
AS number_of_earthquakes
FROM tutorial.worldwide_earthquakes earthquakes
CROSS JOIN (
SELECT year
FROM (VALUES (2000),(2001),(2002),(2003),(2004),(2005),(2006),
(2007),(2008),(2009),(2010),(2011),(2012)) v(year)
) years
View the final product in Mode.
What's next?
Congrats on finishing the Advanced SQL Tutorial! Now that you've got a handle on SQL, the next step is to hone your analytical process.
We've built the SQL Analytics Training section for that very purpose. With fake datasets to mimic real-world situations, you can approach this section like on-the-job training. Check it out! And if you need just a little more practice with pivot tables before you do, check out our 4 handy SQL tips.