






We here at Mode Analytics have been Amazon Redshift users for about 4 years. Redshift enables and optimizes complex analytical SQL queries, all while being linearly scalable and fully-managed within our existing AWS ecosystem. In our early searches for a data warehouse, these factors made choosing Redshift a no-brainer. Redshift has mostly satisfied the majority of our analytical needs for the past few years, but recently, we began to notice a looming issue. Certain data sources being stored in our Redshift cluster were growing at an unsustainable rate, and we were consistently running out of storage resources.
Running Off a Horizontal Cliff
After a brief investigation, we determined that one specific dataset was the root of our problem. The dataset in question stores all event-level data for our application. This type of dataset is a common culprit among quickly growing startups. We store relevant event-level information such as event name, the user performing the event, the url on which the event took place, etc for just about every event that takes place in the Mode app. As our user base has grown, the volume of this data began growing exponentially. By the start of 2017, the volume of this data already grew to over 10 billion rows. (Fig 1.)
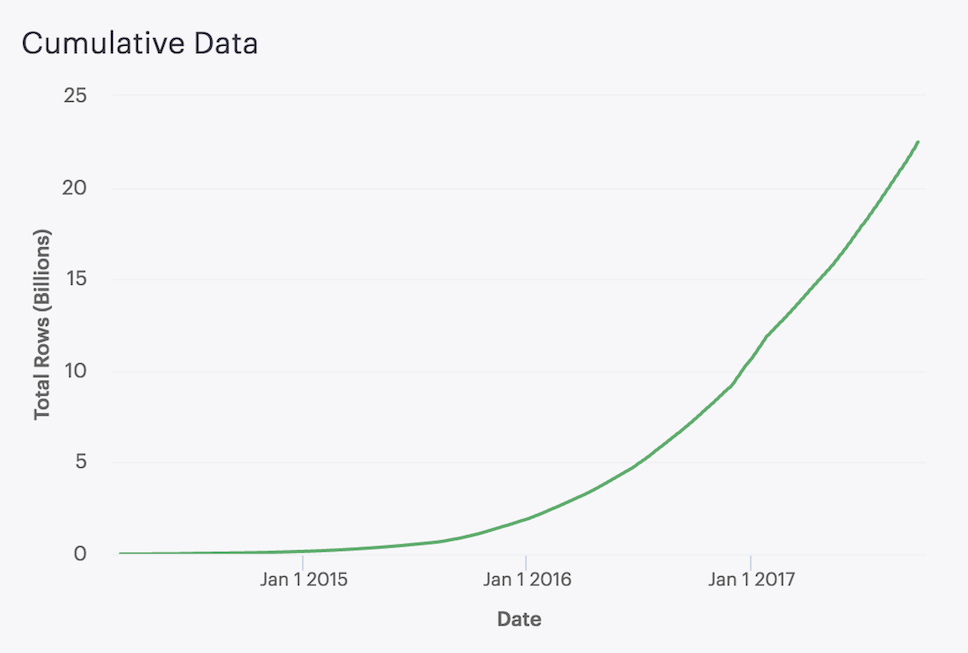 Fig 1. Event-level Data Growth
Fig 1. Event-level Data Growth
In most cases, the solution to this problem would be trivial; simply add machines to our cluster to accommodate the growing volume of data. We hit an inflection point, however, where the volume of data was growing at such a rate that scaling horizontally by adding machines to our Redshift cluster was no longer technically or financially sustainable. To add insult to injury, a majority of the event data being stored was not even being queried often. It simply didn’t make sense to linearly scale our Redshift cluster to accommodate an exponentially growing, but seldom-utilized, dataset. We needed a way to efficiently store this rapidly growing dataset while still being able to analyze it when needed. And we needed a solution soon.
Finding an Elastic Parachute
As problems like this have become more prevalent, a number of data warehousing vendors have risen to the challenge to provide solutions. For example, Google BigQuery and Snowflake provide both automated management of cluster scaling and separation of compute and storage resources. For both services, the scaling of your data warehousing infrastructure is elastic and fully-managed, eliminating the headache of planning ahead for resources. In addition, both services provide access to inexpensive storage options and allow users to independently scale storage and compute resources.
This trend of fully-managed, elastic, and independent data warehouse scaling has gained a ton of popularity in recent years. The data engineering community has made it clear that these are the capabilities they have come to expect from data warehouse providers. While the advancements made by Google and Snowflake were certainly enticing to us (and should be to anyone starting out today), we knew we wanted to be as minimally invasive as possible to our existing data engineering infrastructure by staying within our existing AWS ecosystem. However, as of March 2017, AWS did not have an answer to the advancements made by other data warehousing vendors. That all changed the next month, with a surprise announcement at the AWS San Francisco Summit.
Welcome Redshift Spectrum
In April 2017, AWS announced a new technology called Redshift Spectrum. With Spectrum, AWS announced that Redshift users would have the ability to run SQL queries against exabytes of unstructured data stored in S3, as though they were Redshift tables. In addition, Redshift users could run SQL queries that spanned both data stored in your Redshift cluster and data stored more cost-effectively in S3. Redshift users rejoiced, as it seemed that AWS had finally delivered on the long-awaited separation of compute and storage within the Redshift ecosystem.
This was welcome news for us, as it would finally allow us to cost-effectively store infrequently queried partitions of event data in S3, while still having the ability to query and join it with other native Redshift tables when needed.
But how does Redshift Spectrum actually do this? Mainly, via the creation of a new type of table called an External Table.
External tables in Redshift are read-only virtual tables that reference and impart metadata upon data that is stored external to your Redshift cluster. This could be data that is stored in S3 in file formats such as text files, parquet and Avro, amongst others. Creating an external table in Redshift is similar to creating a local table, with a few key exceptions. You need to:
- Assign the external table to an external schema.
- Tell Redshift where the data is located.
- Tell Redshift what file format the data is stored as, and how to format it.
That’s it. Once you have your data located in a Redshift-accessible location, you can immediately start constructing external tables on top of it and querying it alongside your local Redshift data. For us, what this looked like was unloading the infrequently queried partition of event data in our Redshift to S3 as a text file, creating an external schema in Redshift, and then creating an external table on top of the data now stored in S3. Once this was complete, we were immediately able to start querying our event data stored in S3 as if it were a native Redshift table. After all was said and done, we were able to offload approximately 75% of our event data to S3, in the process freeing up a significant amount of space in our Redshift cluster and leaving this data no less accessible than it was before.
The Long Term View
Unloading this original partition of infrequently queried event data was hugely impactful in alleviating our short-term Redshift scaling headaches. However, this data continues to accumulate faster every day. In a few months, it’s not unreasonable to think that we may find ourselves in the same position as before if we do not establish a sustainable system for the automatic partitioning and unloading of this data.
Data warehouse vendors have begun to address this exact use-case. For example, Panoply recently introduced their auto-archiving feature. Aside from vendor-specific functionality, what this may look like in practice is setting up a scheduled script or using a data transformation framework such as dbt to perform these unloads and external table creations on a chosen frequency. While the details haven’t been cemented yet, we’re excited to explore this area further and to report back on our findings.
Redshift users have a lot to be excited about lately. Pressure from external forces in the data warehousing landscape have caused AWS to innovate at a noticeably faster rate. From Redshift Spectrum finally delivering on the promise of separation of compute and storage to the announcement of the DC2 node type with twice the performance of DC1 at the same price, Redshift users are getting the cutting-edge features needed to stay agile in this fast-paced landscape.
We’re excited for what the future holds and to report back on the next evolution of our data infrastructure. Do you have infrastructure goals for 2018? Topics you'd like to see us tackle here on the blog? We’d love to hear about them! Give us a shout @modeanalytics or at community@modeanalytics.com

