






2017 feels like a turning point for the analytics community—everyone seems to be talking about the sudden proliferation of analytics tools. A technological cell division within our arsenals. Not only is the number of tools increasing, these same tools are also addressing increasingly discrete problems. Whereas we used to evaluate one or two tools to solve an array of data problems, it’s not uncommon now to evaluate a suite of different tools to solve discrete subsets of those same problems.
It’s not hard to understand why this can feel exhausting. Keeping pace with the evolution of the data science & analytics tooling landscape has become a full-time job. Noticing this brings up two higher-level questions:
- Why is this happening?
- Are we benefitting?
There are no right answers. But reflecting on these trends and speculating on their cause can teach us something. There are clear signals that this evolution is not only by design, but is, in fact, is a natural extension of emerging trends we’ve seen in software engineering.
Since analytics needs are highly variable across teams and undergo frequent evolution within teams, this article will not attempt to provide guidance on choosing the tools that are right for you. Instead, we'll shift our focus to understanding the cause of the trends we're observing, and how embracing this evolution and leveraging its benefits may serve as the catalyst to take our analytical capabilities to the next level.
Consider the spork
Have you ever wondered why you don’t see more sporks? In theory, the spork is a revolutionary tool that perfectly consolidates the core functionality of the spoon and fork. The spork should have taken the world by storm, transforming all of us into more efficient eaters and forever freeing up space in our utensil drawers. In practice, all we got was a mediocre spoon and a mediocre fork.
As it turns out, we tend to value discrete functionality in our tools, especially when it results in holistically better performance and user experience. This tenet is central to the Unix philosophy, specifically its Rule of Modularity. Doug McIlroy, the inventor of Unix pipelines and pioneer of component-based software engineering, summarized this philosophy in A Quarter Century of Unix:
Write programs that do one thing and do it well. Write programs to work together.
This concept serves as the foundation of modular programming design, or “code modularity.” The idea is that the holistic functionality of a program should be separated into independent, interchangeable modules. It’s a philosophy that few programmers dispute. With it, we iteratively construct transformative software while minimizing its global complexity. Code modularity also serves as an inspiration for the increasingly popular microservice architecture.
Microservice architecture is not necessarily a new design strategy, but it is one that has seen a surge of interest over the past few years (Fig. 1). Industry leaders including Netflix and Amazon have adopted this design strategy for their internal systems.
Fig 1. "Microservice" Google Search Interest Over Time
So what, exactly, is a microservice?
And, more importantly, how does it relate to our analytics tooling architecture?
At a high level, microservices are small, autonomous services that work together. They are designed with two principles in mind:
- Do one thing, and do it well.
- Be autonomous and loosely coupled to the services that come before or after.
Microservice architectures are known to have a number of benefits, notably:
- Heterogeneity: The ability to use different technologies for different services, allowing us to consistently pick the best tool for a specific job.
- Scalability: The ability to independently scale different services according to need.
- Replaceability: The ability to swap in and swap out individual components without destabilizing the overall system.
Microservices are most often designed around bounded contexts: logical collections of items that have an explicit responsibility. For example, an e-commerce company may choose to design one microservice explicitly for handling orders on their website and a separate microservice explicitly designed to handle shipping those orders. These two microservices are then designed to communicate through an interface such as a REST API.
Microservice architecture is most often thought of as being applied within the context of an individual company codebase. However, as software becomes increasingly easier to deploy and distribute, and microservice architecture becomes increasingly popular, it seems we are bearing witness to a simultaneous increase in the specialization of software itself. In other words, open-source and consumer software is increasingly being designed to embody microservice principles. Instead of an increase in the number of monolithic SaaS provider “platforms,” we’ve seen an explosion in individual contributions, typically in the form of increasingly modular but complementary tools, which provide elegant and robust solutions to increasingly discrete problems.
The modern analytics infrastructure
In a particularly relevant example, let’s take a look at Airbnb’s data infrastructure (Fig. 2). What you see is a highly modularized architecture, with tools chosen strategically for specialized jobs.
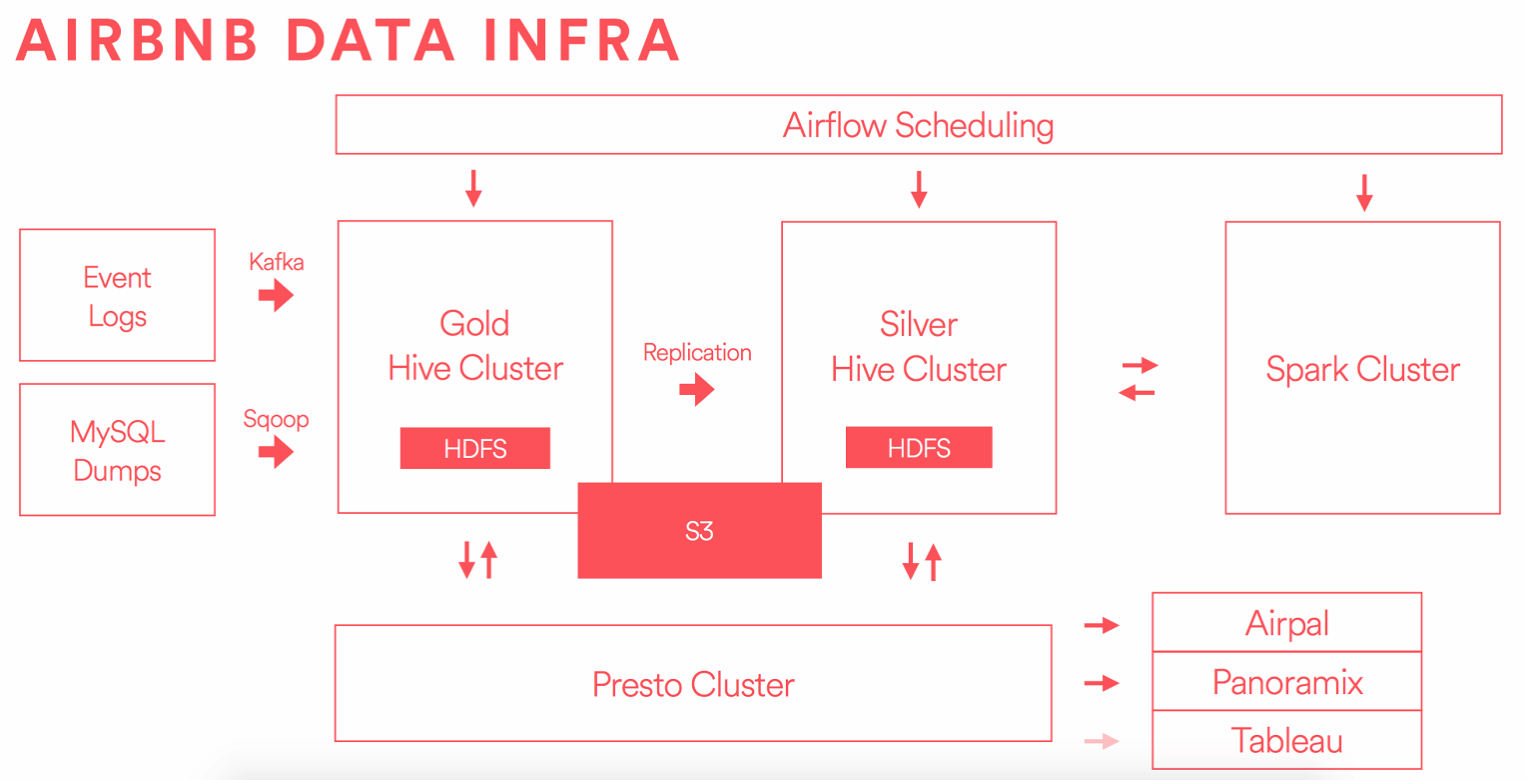 Fig 2. Data Infrastructure at Airbnb source
Fig 2. Data Infrastructure at Airbnb source
Airbnb is not alone here. The most data-informed and data-literate companies in the world are leveraging increasingly modular, microservice-like architectures in their data infrastructure. This framework provides these companies performance and resiliency and allows them to scale efficiently by picking and choosing the best tools to solve discrete problems without disrupting the system as a whole.
But this architectural design-pattern isn’t reserved for the most advanced and resource-rich data teams in the world. There's an increasing number of data tools on the market that aim to empower a broader spectrum of teams with accessible, elegant, and scalable solutions for more discrete problems.
Consider tools such as Stitch, Singer, and Fivetran for data consolidation, Redshift, BigQuery, and Snowflake for data warehousing, or dbt for data transformation. What these tools all have in common is that they are being designed within the bounded contexts of the modern analytics infrastructure (Fig. 3). In choosing this design, they are providing us the foundations to construct evolutionary architectures; architectures that acknowledge and prepare for an inevitable future where technologies become obsolete and requirements change.
 Fig 3. The Bounded Contexts of the Modern Analytics Infrastructure
Fig 3. The Bounded Contexts of the Modern Analytics Infrastructure
A harrowing tale...
As an example, consider the following scenario: You were originally tasked with building a data science team to leverage your company's data. Your data team has grown from 1 to 15 people. You’ve achieved massive success on critical projects, gained trust from your stakeholders, and have delivered tangible business impact. Your next task is to take data science and analytics to the next level. You decide to begin leveraging a new analytics tool that provides more power and flexibility to your team. However, upon deeper inspection, you realize that your data warehouse and data models are tightly coupled to your current analytics tool. You realize that changing tools requires either complete loss of or significant adjustments to your underlying data infrastructure. Taking this project on could be hugely destabilizing to your team and the people who depend on your work. Existential dread sets in. You decide to cut the project and settle for the status quo.
This scenario may sound dramatic, but for many, it's all too familiar. It is a classic example of tight coupling, where services extend and root themselves outside of their own bounded contexts. It leads to unnecessary complications when trying to make modular improvements. A core tenet of microservice architecture is loose coupling, where adjustments can be made to a service without affecting other services. We should architect our data infrastructure to reflect this tenet, and strive to build stacks where changes in one bounded context do not require changes in others.
When constructing a system of modular tools, each tool cannot be built in a vacuum. An ecosystem of isolated tools does no good to anyone. Microservice architecture posits that in order to reap the benefits of the design, the services we build within bounded contexts should be agnostic about the services or technology that come before or after them. Luckily, our data tools are increasingly being designed with this in mind. They are becoming conscious of their place in a larger ecosystem of tooling, and are being designed for integration rather than isolation.
The future is modular
The analytics community is largely gravitating towards tools that embody the core tenets of microservice architecture:
- Do one thing and do it well.
- Design for high cohesion and loose coupling with other tools.
This gravitation is intentional. Data scientists, data engineers, and analysts are starting to recognize the benefits of a modular, microservice-like data infrastructure. This ecosystem allows us to stay agile and lets us make modular improvements in our data stack without it being a destabilizing or invasive procedure. This stability is only becoming more critical as data science and analytics output becomes more and more integral to people’s day to day work.
We should not fool ourselves into believing that today’s solution will be right for tomorrow. Instead, we should embrace change and plan for it accordingly. Building Microservices author Sam Newman puts it elegantly:
... our architects need to shift their thinking away from creating the perfect end product, and instead focus on helping create a framework in which the right systems can emerge, and continue to grow as we learn more.
It’s time we learn from the experiences of architects who have come before us and begin building with an eye for the future.

